Supporting huge traffic in AWS lambda serverless environment
Category: mm
စာမရေးတာတော်တော်လဲကြာပြီ။ ဒီ post က infrastructure ပိုင်း serverless ပိုင်းနဲ့ပတ်သက်တာရေးချင်တာ။ Serverless ကအခုနောက်ပိုင်းပိုနာမည်ရလာတယ် sst.dev လို framework မျိုးတွေကြောင့်ကော infra-as-code နောက် application development/deployment ကပိုလွယ်လာတယ်။ နောက်အဲ့မှာ API ရေးရင်အရင်လို Flask တို့ NestJS တို့လို့ framework တွေနဲ့ရေး Dockerize ပြီး deploy တဲ့အစား AWS Lambda လို serverless function တွေကိုအကြိုက်တွေ့လာကြတယ် (ဥပမာဒီ article မျိုး How we saved hundreds a month by using Serverless)၊ scale တာစဥ်းစားစရာမလိုဘူး idel state ကိုပေးစရာမလိုတော့ cost သက်သာတယ်တို့ကောပေါ့။
1. AWS Lambda
ဒါပေမယ့် Lambda သုံးတဲ့အခါမှာလဲ scale စာစဥ်းစားစရာမလိုဘူးဆိုတာလုံးဝတော့လဲမမှန်ပြန်ဘူး။ AWS Lambda မှာလဲသူ့ limit သူရှိတယ်။ Resource limit အပြင်တခြားစဥ်းစားရမယ့် limitation တွေရှိတယ်။ အဲ့တာတွေက
- Invocation payload limit
- Function timeout
- Concurrent execution limit (အဓိကပြောချင်တာဒီကောင်၊ ဒါမပြောခင်ပေါ်က၂ခုအရင်ပြောဦးမယ်)
Lambda Quota နဲ့ပတ်သက်ပြီးအဲ့မှာသွားကြည့်လို့ရတယ်။
1.1 Lambda invocation payload limit
Lambda မှာက Request/Response limitation တွေရှိတယ်။ Lambda က HTTP အပြင်တခြားလဲသုံးလို့ရတယ်ဆိုပေမယ့်ဒီမှာ API ဘက်ကိုအဓိကပြောမယ်။ သူက Synchronous ဆို 6 MB invocation limit ရှိတယ်၊ Async ဆို 256 KB၊ ဆိုတော့ file upload တာမျိုးဆိုပုံမှန် web server ရေးသလို endpoint လဲပေးလိုက်တာမျိုးကအဆင်မပြေဘူး။ Serverless မှာဆို S3 လိုကောင်မျိုးနဲ့တွဲသုံးမှပိုအဆင်ပြေတယိ။ ဆိုတော့ File upload လိုလာရင် Lambda က presigned URL generate ပေးပြီး respond တာမျိုးလုပ်တာပိုအဆင်ပြေတယ်။ ပြီးမှ file upload ကအဲ့ presigned URL ကိုခေါ်တာမျိုး။ အလုပ်ရှုပ်တာကလွဲရင်အဲ့လောက်အဆင်မပြေတာ မျိုးတော့မဟုတ်ဘူးပေါ့။
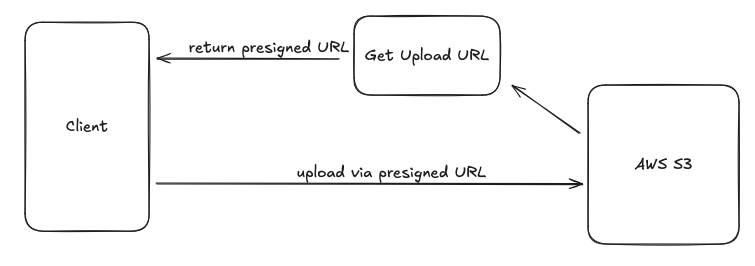
API Response မှာလဲဒီ invocation payload limit ကိုထည့်စဥ်းစားဖို့လိုတယ်။ Payload limit exceed ဖြစ်ရင် executation fail သွားမှာပေါ့။
1.2 Function timeout
ဒါကတော့ရှင်းတယ်။ Lambda မှာက ၁၅မိနစ် timeout ရှိတယ်။ ပြောချင်တာက Lambda ကိုအဲ့ထက်ပို run ကို run လို့မရဘူး။ Background task တွေဆို ၁၅မိနစ်ထက်ပိုမယ်ဆို AWS Batch Job လိုကောင်မျိုးသုံးပေါ့။ ဒီမှာလဲ API ဘက်ကနေပြောချင်တယ်။ Lambda က 15 minutes timeout ရှိတယ်ဆိုတိုင်း API response time က 15 minutes ဖြစ်မှာမဟုတ်ဘူး။ ဘာလို့လဲဆို AWS Lambda ကို API အနေနဲ့တန်းမ run သင့်ဘူး။ ရှေ့မှာ API Gateway ရှိမယိ။ ဘာအတွက်လဲဆို
- rate limit
- caching
စတာတွေအတွက်ပေါ့။ REST API Gateway မှာဆို default က 29 seconds timeout ရှိတယ် (နောက်ပိုင်းတော့ increase လို့ရပြီ) ဆိုတော့ Lambda က 15 minutes run လို့ရရင်တောင်ရှေ့က API Gateway က 29 seconds ဆို response ကအဲ့အတွင်းမလုပ်ရင် API Gateway ကဖြတ်ချပြီး 504 Bad Gateway response ပဲပြန်လိမ့်မယ်။
1.3 Concurrent execution limit
Scaling ပိုင်းနဲ့ပတ်သက်ပြီးအဓိကပြောချင်တာကဒီအပိုင်းပဲ။ Infrastructure scaling လုပ်ပြီးဆိုအကုန်လုံးတွေးရတော့တာပဲ။ ဥပမာ Database ပါပြီဆိုရင်သူ့လဲသပ်သပ် scale ရတယ်။ Read/Write cluster ခွဲတာမျိုးနောက် Read replica တောင်ထပ်ခွဲသင့်ခွံတာမျိုး၊ ပြောရရင် API Read နဲ့ကိုယ့် frontend server အတွက် Read replica သပ်သပ်မျိုးအဲ့တော့မှ API က load များလို့ကျသွားရင်တောင်ကိုယ့် frontend app ကကျမသွားအောင်။
အဲ့မှာကိုယ်က serverless သုံးရင် scale တဲ့အခါထည့်စဥ်းစားဖို့လိုလာတာက Lambda concurrent execution limit။ Original document ကဒီမှာသွားဖတ်ကြည့်လို့ရတယ်။ Lambda မှာက 1,000 concurrent executation limit ရှိတယ်သူက AWS region level။ ပြောရမယ်ဆိုကိုယ့် Lambda က Singapore ap-southeast-1 မှာဆိုဒီ executation limit က region တစ်ခုလုံးကိုထည့် count တာ။ ကိုယ့်အကောင်က Singapore region မှာ 1,000 ထက်ပို run လို့ရကိုမရဘူး။ ကျော်တာနဲ့ error တက်တာ။ Service Quotas Dashboard ကနေတော့ limit ကို increase လို့ရတယ်ဒါပေမယ့်အဲ့တာ scaling အတွက် right solution မဟုတ်ဘူး။ ကိုယ့် app က spike traffic မှာ 100k - 200k ဆို limit ကိုသွားပြီး ၁သိန်း၂သိန်းတင်ခိုင်းနေလို့အဆင်မပြေဘူး။
ဒီတော့ Lambda သုံးရင် RDS scale ထားရင်တောင်ဒီကောင့်ကလာပြီး bottleneck ဖြစ်နိုင်တယ်။
2. Cloudflare
ဒီတော့ Scaling အပိုင်းပြောဖို့ Cloudflare ဘက်ကိုဆက်မယိ။ အဲ့တော့ Lambda API scale ဖို့ဆို Cloudflare နဲ့ကသင့်တော့တယ်။ အလုပ်မှာ service ကရှေ့မှာ Cloudflare ခံထားတာအဲ့တော့ Cloudflare ကသာ cache သေချာလုပ်ထားရင် AWS ကို request ကလာစရာကိုမလိုတော့ဘူး။ Cloudflare Edge Network ကနေပဲ response မယ်။ Scaling လဲအဆင်ပြေမယ်၊ edge network ဖြစ်လို့ response time လဲနည်းမယ်။ ဒါပေမယ့်ဒီမှာလဲစဥ်းစားဖို့လိုတာတွေရှိတယ်။ Cloudflare Cache က silver bullet မဟုတ်ဘူး။
Cloudflare Caching Rule အလုပ်လုပ်ပုံက URL pattern ပေါ်မူတည်ပြီး Edge TTL cache ကို configure လို့ရတယ်။ ဥပမာကိုယ့် API data ကတော်တော်ကြာကြာပြောင်းလေ့မရှိဘူးဆို Edge TTL ကို 1 year အထိထားလို့ရတယ်။ နားလည်လွယ်အောင် diagram နဲ့ဆွဲပြရမယ်ဆိုဒီလိုမျိုး။

ဒီမှာတယ်တော့သိပ်နားမလည်ကြတာတစ်ခုရှိတယ်။ Edge TTL အလုပ်လုပ်ပုံက 1 year ထားတိုင်း Cloudflare Edge Network မှာ 1 year အထိထားပေးတာမဟုတ်ဘူး။ ဒါကိုကျွန်တော်လဲအစကသဘောမပေါက်ခဲ့ဘူး။ အလုပ်မှာ campaign တစ်ခုအတွက် service လုပ်နေတာအဲ့မှာ cache ကို pre-warm လုပ်ထားမယ်ပေါ့ all possibilites တွေအကုန်ကြို cache ထားချင်တာ Edge TTL configure ပြီး script နဲ့ API request combination အကုန်ထိုင်ခေါ်နေတာနောက် 1 နာရီလောက်နေတော့ပြန်ခေါ်ကြည့်တာ HTTP Response Header
မှာဘာလို့ cf-cache-status: EXPIRED ဖြစ်လဲပေါ့ဆိုပြီးလိုက် debug ကြည့်တော့မှာဒါကိုသိတာ။
Discussion ကိုဒီမှာဖတ်ချင်ဖတ်ကြည့်လို့ရတယ်။ TLDR ပေးရမယ်ဆို Edge TTL cache duration အလုပ်လုပ်ပုံက 1 year ပြောထားရင် Cloudflare က Edge Servers တွေမှာ 1 year cache ခိုင်းတာထက် 1 year cache လို့ရတယ်လို့ပြောချင်တာ။ ကိုယ်က 1 year ပြောထားလို့ 1 year အထိ cache ပေးမှာမဟုတ်ဘူး။ သူ့မှာ internal caching mechanisms တွေရှိတယ်ကိုယ်က 1 year ပြောထားရင်တောင်ဒီ resource ကသိပ်မသုံးဖြစ်ဘူးပြောရရင် Cache Hit သိပ်မဖြစ်ဘူးဆို auto edge servers တွေကနေဖျက်ပစ်တယ်။
ဆိုတော့ကိုယ်တော်ဥပမာပေးရမယ်ဆိုကျွန်တော့်မှာ campaign က peak concurrent traffic က 300k-400k (၃သိန်း၄သိန်း) HTTP requests ဝင်မယ်ဆို AWS Lambda ကိုတိုက်ရိုက်ထိဖို့ကအဆင်မပြေဘူး။ Edge TTL ကလဲ campaign မတိုင်ခင် pre-warm လုပ်ထားဖို့ကအဆင်မပြေဘူး Cloudflare က Cache Hit မဖြစ်တာကြာရင်ဖျက်ချမှာ ပြီးတော့ HTTP payload combination က 1 million, ၁၀သိန်းလောက်ရှိမယ်ထားပါတော့ဆိုတော့ Cache ကလဲလုပ်ကိုလုပ်ထားရမယ်။
2.1 Cloudflare Workers and Workers KV
Solution မပြောခင်ဒီမှာတချို့ကပြောမယ် Redis သုံးပေါ့ဘာညာ။ ဘာလို့အလုပ်မဖြစ်လဲပြောပြမယ်။ Redis ကဘယိနေရာမှာအဆင်ပြေမလဲဆို Lambda နဲ့ RDS ကြား cache ချင်ရင်။ ပြောရရင်အောက်ကလို

Lambda က Redis မှာအရင် check မယ်မရှိရင် RDS ကနေဖတ်ပြီးတော့ Redis ထဲမှာ save ဒီတော့နောက် request တွေက Redis ကတန်းဖတ်လို့ရအောင်။ ဒါပေမယ့်ဒီ solution ကအပေါ်က problem မှာအလုပ်မဖြစ်ဘူး။ ဘာလို့လဲဆို RDS က bottleneck မဟုတ်ဘူး။ Bottleneck က Lambda မှာ။ ဒီတော့ Redis ထည့်လဲ Lambda concurrent execution limit ကဖြစ်မှာပဲ။ Solution က Cache ကို client နဲ့အနီးဆုံး edge ဘက်မှာထားရမှာ။ ပြောရရင် orange cloud aka Cloudflare မှာ AWS မှာမဟုတ်ဘူး။
Solution ကဘာလဲဆိုတော့ Edge TTL cache တိုက်ရိုက်လုပ်မယ့်အစားကြားထဲမှာ Cloudflare Worker ကို proxy အနေနဲ့သုံးပြီး Workers KV ကို cache အနေနဲ့သုံးတာ။
Cloudflare workers က proxy အနေနဲ့အလုပ်လုပ်မယ်ဆိုတာသူက Client/Frontend ကနေ request ကိုလက်ခံမယ်။ ပြီးရင် Workers KV မှာရှိမရှိ check မယ်မရှိရင် Lambda ကိုလှမိးခေါ်မယ်ပြီးရင် Workers KV မှာလာ save မယ်ပြီးရင်ပြန် response မယ် client ကို။ ပြောရရင်အောက်ကလိုမျိုး

Redis နဲ့တူတယ်ဒီမှာမတူတာက Workers KV ရှေ့က Edge servers ကဘာလို့ပါနေလဲပေါ့။ ပြီးမှသပ်သပ်ရှင်းပြမယ်။ အခုလို solution ဆိုအပေါ်က problem အတွက်အဆင်ပြေသွားပြီ။ ဥပမာကျွန်တော်က HTTP payload combination လံကြိုသိတယ် 1 million ဆိုအကုန်လုံးက campaign မစခင်မှာထဲက cache ကို warm ကြိုလုပ်ထားလို့ရတယ်။ အဲ့တော့ Lambda ကထိကိုမထိတော့ဘူး။ Workers KV ကနေပဲဖတ်မယ်တန်း response မယ်။ Peak concurrent traffic က 300k-400k ဆိုလဲ RDS scaling တို့ Lambda concurrent execution limit တို့ကိုပူစရာမလိုတော့ဘူး။
အဲ့တော့ပြောဖို့ကျန်တာက KV ရှေ့က Edge Servers တွေ။ Cloudflare စီကပဲ image ကို copy လိုက်တော့မယ်။ Original document ကိုဒီ How KV works မှာသွားဖတ်ကြည့်လိုရတယ်။

KV မှာ hot and cold read ဆိ်ုတာရှိတယ်။ Cloudflare worker က Lambda ကနေဖတ်ပြီး KV မှာ save ရင် Cloudflare က central storage တစ်နေရာမှာသွား save တာ။ KV ကနေ worker ကပြန်ဖတ်တဲ့အခါက user request location ပေါ်မူတည်ပြီး edge servers က client နဲ့အနီးဆုံး location တွေစီမှာ Cloudflare က KV data ကိုထပ် cache တယ်။ ပြောရမယ်ဆိုကျွန်တော် Lambda ကလာတဲ့ response ကို Cloudflare worker က India က central storage တစ်ခုမှာ save လိုက်တယ်။ နောက် user က Singapore ကနေခေါ်တဲ့အခါ Singapore Edge Server မှာရှိရငိ worker ကအဲ့ကနေဖတ်ပြီး client ကိုပြန် response မယ်။
Lower latency, faster response time ပေါ့။ မရှိရင် India က central storage ကနေဖတ်မယ်၊ Singapore က edge server မှာသိမ်းမယ် user ကို response မယ်။ ပြောရရင်ကျွန်တော် Lambda က Cloudflare KV central storage အလုပ်လုပ်သလိုပဲ။ ဒါကို Cloudflare က hot and cold read လို့ခေါ်တယ်။ Central server က read တာက cold read၊ Edge server က read တာက hot read။
ဒီ hot read အတွက် edge server မှာသိမ်းတာကိုလဲဘယ်လောက်ကြာကြာ cache လို့ရတယ်ဆိုတာကို configure လို့ရတယ်။ Default က 60 seconds ပဲ။ ဒီမှာဖတ်ကြည့်လို့ရတယ်။ ဒီ configuration ကကိုယ့်လိုအပ်ချက်ပေါ်မူတည်တယ်။ Cache TTL (time-to-live) များရင် Edge server မှာကြာကြာသိမ်းမယ်။ Faster respones time ဒါပေမယ့် Cache discrepancy ပိုကြီးမယိ။ KV central storage မှာ save ပြီးအချိန်တစ်ခုကြာမှ Edge server မှာ reflect လာဖြစ်မယ် TTL ပိုကြာရင်။
ဒီ post ကတော့ဒီမှာပဲဆုံးပြီ။ ဒါကလက်ရှိအလုပ်မှာကြုံရတဲ့ case တစ်ခုနဲ့ပတ်သက်ပြီးပြန် share ချင်ရုံသက်သက်ပေါ့။ Serverless optimization နဲ့ပတ်သက်ပြီး share ချင်တာလဲတစ်ပိုင်းပေါ့။